- TheTechOasis
- Posts
- Meta's Multi-token Paradigm & Google's Pixel Sound Predictor
Meta's Multi-token Paradigm & Google's Pixel Sound Predictor
Ignacio de Gregorio Noblejas
July 11, 2024
🏝 TheTechOasis 🏝
part of the:

Welcome to the newsletter that keeps you updated on the latest developments at the cutting edge of AI by breaking down the most advanced systems in the world & the hottest news in the industry.
10-minute weekly reads.
🚨 Week’s Update 🚨
Welcome back! This week, we have news from Groq, Figure, OpenAI, Cognizant, & more.
Starting strong, Groq unveiled new features you can try on their website for free with ultra-fast throughput. This article includes video examples for inspiration.
Groq’s insane capabilities really give a perspective on how narrowed the industry’s focus is on GPUs, while other hardware like LPUs offer better performance at scale.
And once Etched.ai launches Sohu, things might start getting ‘interesting’ for NVIDIA’s dominance in LLM inference workloads.
In a recent study, Cognizant and Dataiku commented on enterprises' increased adoption of GenAI.
Let’s not get carried away with the hype and follow the money. We need less “yeah we are deploying GenAI” marketing stunts and more “stop bluffing and give me your core budget number for GenAI”.
The truth? Only 33% of companies have moved on from the experimental phase, aka no serious commitments for the time being.
Writer, one of the few GenAI companies that seem to be experiencing this unusual feeling called ‘having revenues,’ has announced new features, including a graph-based RAG pipeline.
The interesting thing to mention here is how knowledge graphs seem to be gaining momentum in the retrieval augmented space to detriment of vector databases, meaning we might be lowkey transcending to a new, more robust enterprise architecture.
SenseTime has announced a model, SenseNova 5.5, that allegedly surpasses GPT-4o in 5 out of 8 critical benchmarks.
In the latest issue of “China is catching up quickly” series, SenseTime really pushes the boundaries, putting to shame all those claims that ‘China is years behind’.
In fact, are they actually behind?
Talking about politics, both Apple and Microsoft have relinquished their board seats at OpenAI, amidst consistent scrutiny by regulators considering the—obvious—consolidation of the LLM market.
Finally, on more futuristic news, Figure AI has published a video with its partner BMW in which a humanoid is seen working in one of the latter’s factories.
As shown in the video, the robot is capable of autocorrecting the position of the metal piece. Seeing these robots self-correcting this early in robotics is truly remarkable.
🧐 You Should Pay Attention to 🧐
🤩 Meta’s New Model Paradigm
🤯 Google Predicts Sounds from Pixels
🤩 Meta’s New Model Paradigm 🤩
Have we discovered a better way of training Large Language Models (LLMs)?
This is what Meta is promising with its new research: it presents a model that predicts multiple tokens at once in every prediction, not just one, and with no training overhead.
This speeds up the model's text generation and, incredibly, makes it smarter, suggesting a new training paradigm for frontier AI.
With this article, you will learn about an interesting new paradigm that could be foundational for future LLM training, but you will also gain nice intuition on why they work the way they work.
A Weak Form of Learning
To comprehend how industry-changing Meta’s research could be, we must understand how LLMs are taught what they know.
A Universal Task Interface for LLMs
When training a deep neural network, you must define the task you want the model to optimize.
In the LLM case, that task is next-word prediction; a model receives a set of input words in the form of a text sequence and predicts the next token (a word or a subword). Then, as with all neural networks today, we find a way to evaluate the prediction quality (the error) as a signal to tune the model.
However, Meta’s model doesn’t just predict one word.
As we want our model to be capable of modeling the entire written language and to be creative when required, we force it to assign a probability to every single token in its vocabulary.
This way, the model has to factor in uncertainty, as many different words might be reasonable continuations to any given sequence. As shown below, for the sequence “The boy went to the…”, all five options are ‘semantically valid,’ but only one is the actual answer.

So, how do we measure the error in this situation?
How LLMs Learn
In an LLM’s case, we do so through the cross-entropy function, which only focuses on the probability the model has assigned to the ground truth.

The Cross-Entropy function
Using the example above, we look at the probability the model assigned to the actual next word, ‘Playground,’ which is 40%. This is well below what it should have been (100%), so the model has plenty of room to tune its parameters.
But why do we learn this specific task?
If you create a model that, for almost any given sequence, can confidently predict what comes next, that model becomes capable of speaking the language, translating between languages, performing very basic reasoning, and so forth.
In other words, predicting the next token task has become universal, and everyone follows this method to train their LLMs.
When it comes to inference, we perform autoregressive decoding.
In layman’s terms, the model always looks backward, not forward. Thus, the probability of any given word generated depends on the words that came earlier.
Now, Meta suggests we should change all this. But how… and why?
Let’s Predict More Tokens!
Meta proposes a new training paradigm.
A New Architecture
In succinct terms, we modify the LLM to predict the next ‘k’ words instead of the next word (they settled for 4, so we will use that number hereon).
For that, we add extra output heads to the model, similar to the Greek mythology beast the Hydra, with each head performing the same exercise: predicting the next four tokens in a sequence.
To be clear, it does not mean that the total predicted tokens are 16. While all four heads produce 4 tokens, we are just keeping the last one out of each head (denoted as words 5, 6, 7, and 8 in the image below).

Source: Meta
For instance, for the famous John Lennon verse “You may say I’m a dreamer, but I’m…” a standard LLM would predict “not,” then “the,” then “only,” and finally “one.”
On the contrary, Meta’s model would predict the entire ending in one turn.
In inference, we can discard the additional heads and perform standard next-word prediction. Alternatively, we can leverage all heads and increase generation speed by up to three times.
However, at this point, you may be asking: if we predict one token at a time and discard the other heads, why bother training the model to predict four tokens simultaneously?
A Smarter Learning Process
The main takeaway from this research is not to make LLMs faster but to make them smarter.
Nonetheless, these models obtain remarkably better results than the standard LLM architecture when trained at scale for code, as evidenced by the results for MBPP or HumanEval coding benchmarks.
When measured at a certain scale (3 billion parameters onward), the 4-token prediction models heftily surpass the ‘might’ of standard LLMs.

But why does this happen? Why is multiple next-token prediction creating better models?
Not all Predictions are Created Equal
It’s important to note that all output heads share the same LLM backbone (depicted as ‘shared’ in the diagram we saw earlier). This means all heads use the same representation to predict the next four tokens.
Simply put, for this to work well, this shared representation must consider not only previous words but also the likely potential next words to the one it’s predicting at any given moment.
In a way, contrary to standard LLMs, this new paradigm forces the model to ‘look forward in time’.
This is particularly important when realizing that not all predictions are equal. While some words directly impact the next words, a term the researchers refer to as a “choice point,” other predictions might be inconsequential to those coming next.
I know this is hard to grasp, so let’s look at an example of both:
Choice point
“The hero entered the dark cave, unsure what he might find. Suddenly, he heard a…”
At this point, the next predicted word can significantly affect the story's direction. For instance, if the model predicts “roar” and then predicts “coming from a rat,” that would be nonsensical. Thus, “roar” seriously constrains the next predictions.
Inconsequential Prediction
Now, consider a context where a character performs a mundane task: “She picked up the pen and started to…”
Here, the next predicted word is likely inconsequential to the overall narrative. For example, whether the next word is “write,” “draw,” or “doodle,” the story remains the same; the outcome doesn’t change.
The point I’m trying to make is that by training a model to predict the next, let’s say, 4 tokens, the model will be much more likely to be aware of whether the next prediction is of high risk if performed wrongly (choice point), improving generation quality.
Another intuition as to why next-token prediction enhances performance is that it reinforces local patterns.
Syntax is Subtle
In standard next-word prediction, each word is independently predicted, and while LLMs can still learn patterns between words close to each other (they learn that “I play the guitar” is correct and “I guitar the play” is not), if we are forcing the model to predict all four at once, the model will learn to produce the tokens in that order, eliminating the chances the second generation ever appears.
This also explains why the best results have been observed in coding.
Syntax errors in coding are much more subtle and have a tremendous negative impact (the code does not work), meaning that while LLMs rarely make syntax errors in natural language, they rarely write perfect code.
Thus, with multi-token prediction, we allow LLMs to learn these short patterns so that the model can output the entire pattern simultaneously.
Moving beyond quality, naturally, these models are faster, too.
Outrageously Fast
One method Meta proposes to enhance speed for multiple-head decoding is Medusa, created by researchers at Together.ai, which increases generation speed up to three times compared to standard LLMs.
In Medusa, each head gets assigned one position in the generative process. If you have four heads, each is charged with predicting one token (first head the first, second head the second token, and so forth).
With the top-k predictions of tokens for each position ready, the model builds a set of candidates, who are chosen using the following heuristic: the longest syntactically valid candidate is chosen.
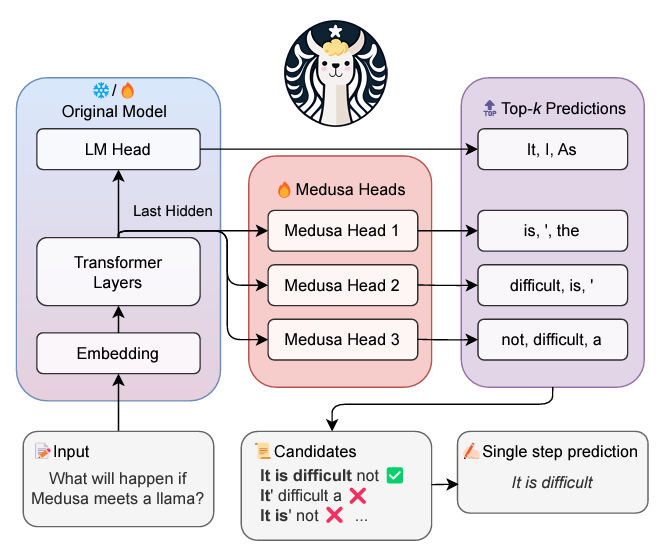
Source: Together.ai
This way, models can write insanely fast, which can be critical for performance, especially when they run large batches (when they provide a service to multiple users at once).

TheWhiteBox’s take
Technology:
Is this the future of LLM training?
In terms of architecture, this is a big deal, as we could eventually change how we train all frontier LLMs. While I’m not convinced this will be the case for text (the results in that modality weren’t that impressive), it has a very high likelihood for coding models.
Products:
Generating correct code is a key requirement not only for coding models, but also for agents, as they must interact with third-party systems (APIs). Improving how we train these models could be a huge enhancement for companies that train them.
Markets:
And who are the people building the aforementioned products?
Public markets: Microsoft (Copilot), Amazon (Alexa), Alphabet (Gemini for Google Cloud), Meta, Apple (Apple Intelligence)
Private markets: Imbue, Adept (acquihired by Amazon), Rabbit (most likely a scam), Cognition Labs (Devin), or Anthropic (Claude), among others.
Most, if not all, private players are invested by either Microsoft, Alphabet, or Amazon. So either way, they are winning.
🤯 Google Predicts Sounds from Pixels 🤯
In what might be one of the most impressive models in quite some time, Google Deepmind has presented a video-to-audio model that takes in video and generates the matching audio.
The model detects car drifts, horror themes, or accurate drum playing, and Google’s insights on how they did it provide invaluable intuition on how AI audio is generated, as well as their plans for some of its key products.
But how does it work?
Diffusion is King
In frontier AI, we have two dominant architectures: autoregressive transformers, like ChatGPT or Gemini, or diffusion transformers (Sora, Veo, or Stable Diffusion).
Autoregressive transformers model sequences by using prior words in a sequence to predict the next one
Diffusion transformers model sequences by denoising a noisy canvas until you get the result.
While the former is the absolute king of LLMs, the latter is the undisputable standard in modeling images or video.
But how does Diffusion work?
From Stone to Statue
For the sake of length, we will use my best analogy: marble sculpturing. Um, what? Bear with me.
The great Rennaissance artist Michelangelo once said:
“The sculpture is already complete within the marble block, before I start my work. It is already there, I just have to chisel away the superfluous material.”
Diffusion is this process applied to AI.
We have an initial, randomized noisy canvas (be that a noisy image, noisy audio,…), and the model, by conditioning on the input prompt (a cue to guide the generation), slowly ‘chisels away the excess material’ (noise) using a fixed number of time steps (it doesn’t do it in one go) until you are left with the result.

Michelangelo would have been a great diffuser
So, what is the diffusion model actually learning to do?
In a more technological sense, the model learns the distribution of the training data (just like LLMs) but is capable of taking random distributions (pure noise) and ‘flowing’ them into its target distribution conditioned on the user’s prompt (“draw me a cat portrait”).
In other words, diffusion models learn to ‘uncover’ the image or video ‘hidden’ beneath all that random noise.
But what do we mean by conditioning?
We want a specific outcome!
Most models today are ‘x-to-x2’, where ‘x’ represents a human desire (“I want whatever”) and can be expressed in various ways (text in the case of ChatGPT), and ‘x2’ represents the way the model will output what you want (text or images in ChatGPT).
Both ‘x’ and ‘x2’ are sequences of tokens, hence why all these models are considered ‘sequence-to-sequence’.
However, in the case of Diffusion models, the schematic is slightly different:

Generated by author
Here, the inputs to the model are twofold:
The Gaussian (random) canvas, aka the noisy distribution
The user condition
Consequently, the diffusion process involves denoising the noisy distribution using the user’s cue so that the outcome semantically matches the condition (they represent the same thing).
In technical terms, the user condition impacts how the model predicts the noise that is going to erase at every time-step through the use of cross-attention layers.
Finally, knowing all this, how does Google’s Video-to-Audio (V2A) work?
From Pixels to Sound
Now that we know how diffusion works, the rest is easy to understand. V2A looks like this:

Source: Google
As expected, the model conditions on two things:
The video we want sound on
Positive and negative prompts: The positive signal what we want, the negative prompts what we don’t want
The inputs are then encoded into vector representations and merged
From random audio (pure noise), the model denoises that audio using the three conditions.
After the denoising process ends, we have our desired audio, but in a compressed form (in the form of a vector, not actual sound).
This compressed representation is decoded into a mel-spectrogram (a snapshot of the audio representing the intensity at every frequency).
Finally, some element (probably a vocoder) converts the mel-spectrogram into actual audio waves and overlaps it with the video.
Et voilà, you have a model that can take videos and a human cue to generate overlapped audio with high semantic fidelity to the video frames.
TheWhiteBox’s take:
Technology:
Once again, all boils down to the attention mechanism, the quintessential component of all things AI today.
Insightfully, Google acknowledged they also tried a pure autoregressive approach (where the audio would have been generated in a next-token manner similar to ChatGPT), but diffusion offered better performance.
Therefore, diffusion is not only the primary choice to model images and video; it’s now for audio, too.
Products:
Based on Google’s acknowledgment, this model will be part of their video generation model, Veo, their rival to OpenAI’s Sora. Moreover, we can see Google’s short-term play from a mile away here: YouTube.
Nonetheless, they’ve just released an eraser feature that allows you to eliminate sound from specific video segments (to avoid copyright claims), meaning they are really betting hard on AI for their video platform.
Markets:
For quite some time, people have speculated that AI is moving on from text-based models (LLMs) to video models (VLMs). In that scenario, nobody is better positioned than Google and its PetaBytes of video data, period.
Google has a huge lead here, not OpenAI or Anthropic.
At the other end of the spectrum, freelance video editors have another reason to reconsider their career choices, as all of Google’s recent moves signal they are venturing into all things video editing.
🧐 Closing Thoughts 🧐
With Meta’s bombshell, we have learned how the industry might reconsider how it trains LLMs, especially regarding coding and agentic tasks, and we have learned great insights into why they work the way they work.
Also, we have seen yet another proof of how ubiquitously powerful—and essential—the attention mechanism is to model every single damn thing in today’s AI, even allowing the creation of unique audios to match our desired video.
That said, I insist that the reason I talk about things like attention is that, in an industry where everything seems to be changing every week, knowing what doesn’t change (attention, diffusion, etc.) is what gives you the edge over others.
Finally, in this Sunday’s Premium segment, we will tackle one of the most pressing questions in AI today:
Is AI actually intelligent?
Until next time!
Give a Rating to Today's Newsletter |
Do you have any feelings, questions, or intuitions you want to share with me? Reach me at [email protected]